Semantic classification bridge
The Semantic Classification Bridge is a data modeling design pattern used to represent complex product attributes in a reusable and scalable way. Instead of relying on flat enums or repeated fields inside product shapes, this pattern separates classification data into dedicated documents that can be enriched, related and shared across many products. This provides better consistency, supports localization, and improves the storytelling capability of product data.
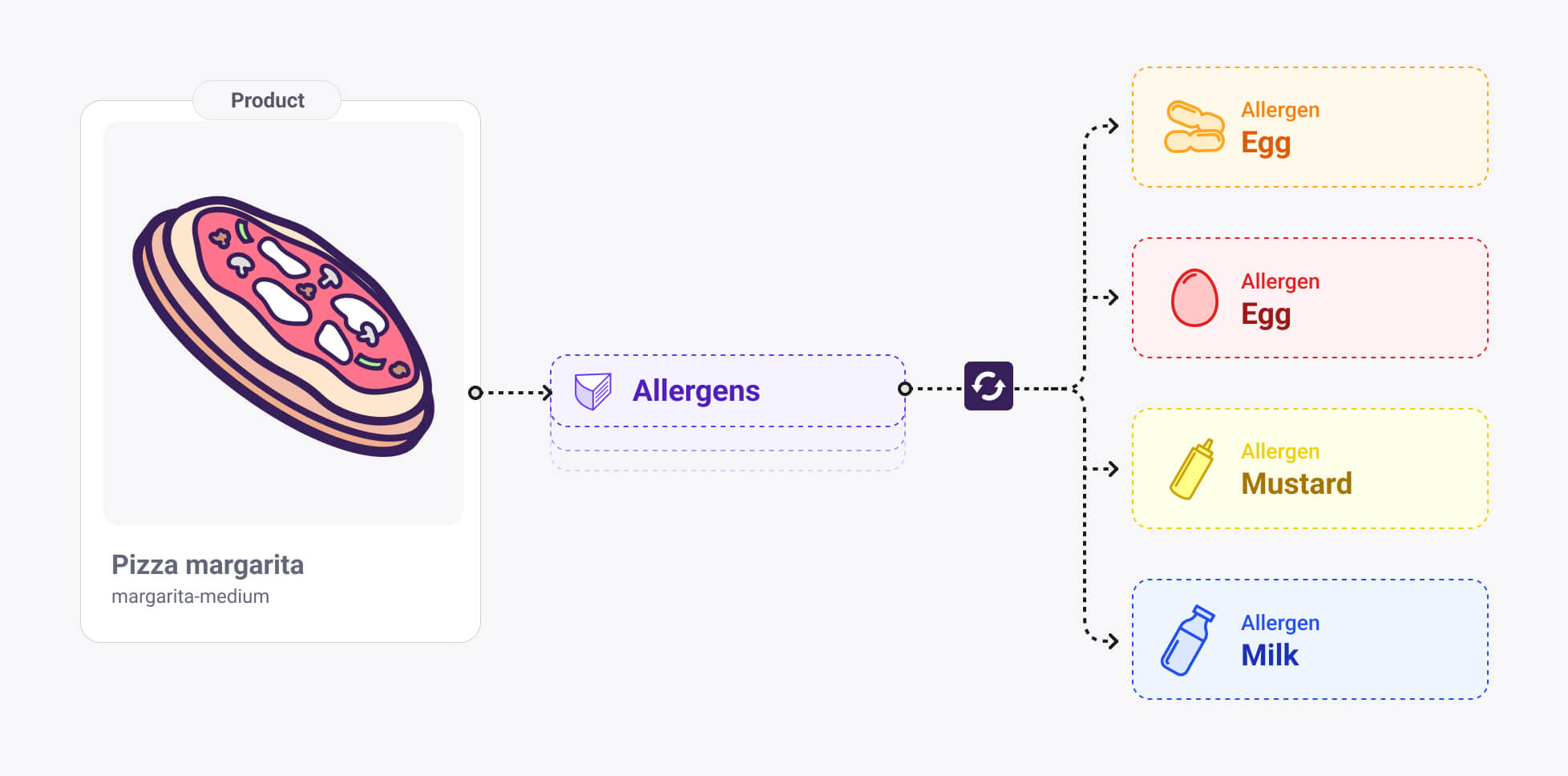
Concept overview
The semantic classification bridge separates product identity from classification logic.
Products keep their core data. Classification is represented as independent documents that may include descriptions, imagery, metadata and relations. The bridge is created by linking products to these classification documents using reference components. This enables a flexible and expressive product model that can evolve without structural changes to product shapes.
When and why to use it
Using classification as separate documents allows for richer storytelling and governance across large catalogues.
Key benefits:
- Maintain consistency across many products that share the same classification.
- Add richness over time, such as descriptions, images, certification details or market-specific notes.
- Reduce duplication of attribute definitions inside product shapes.
- Support localization by storing translated or region-specific detail directly in the classification documents.
- Support for searching, filtering and faceting via the Discovery API.
Use this pattern when:
- You have product groups with shared structured meaning (e.g., allergens, materials, brands).
- You need to update shared meaning once and have it reflected across many products.
- You want to enable richer content around classifications, not just a list of attribute values.
Implementation in Crystallize
In Crystallize, classifications are modeled as documents with their own shapes. Products reference these documents via component relations.
This allows:
- Shared classification documents to act as the canonical meaning source.
- Products to stay lightweight and focused on variant data like pricing, stock and images.
- Classification documents to evolve independently without requiring product model migrations.
A typical approach is:
- Create a shape for the classification document (for example, Allergen, Material or Brand).
- Create documents in that shape representing the classification values.
- Add a Component of type Item Relations to the product shape.
- Link the product to the classification documents.